xv6内存布局
注
聊聊xv6的内存布局 以及更详细的一些关于页面的知识
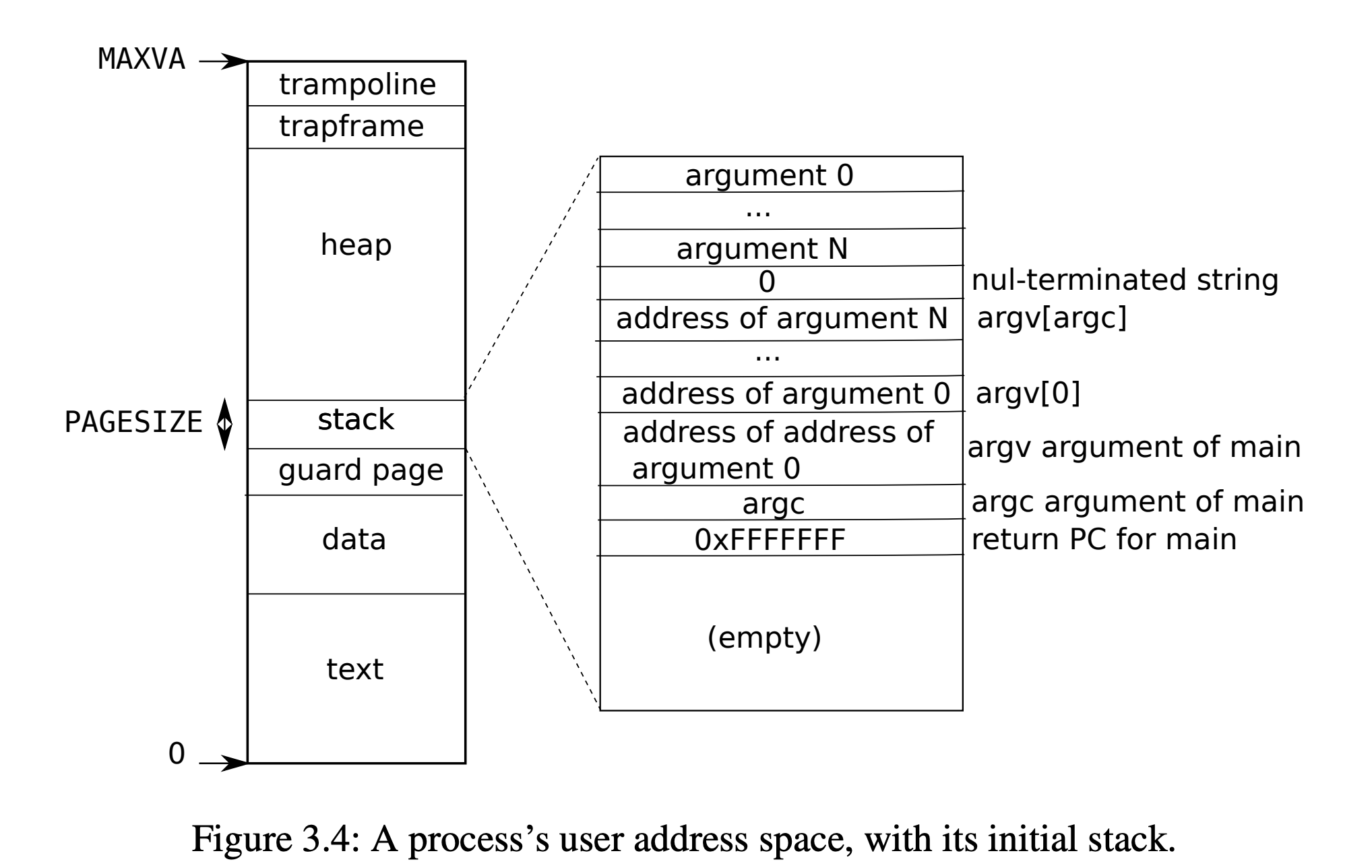
用户进程的内存布局
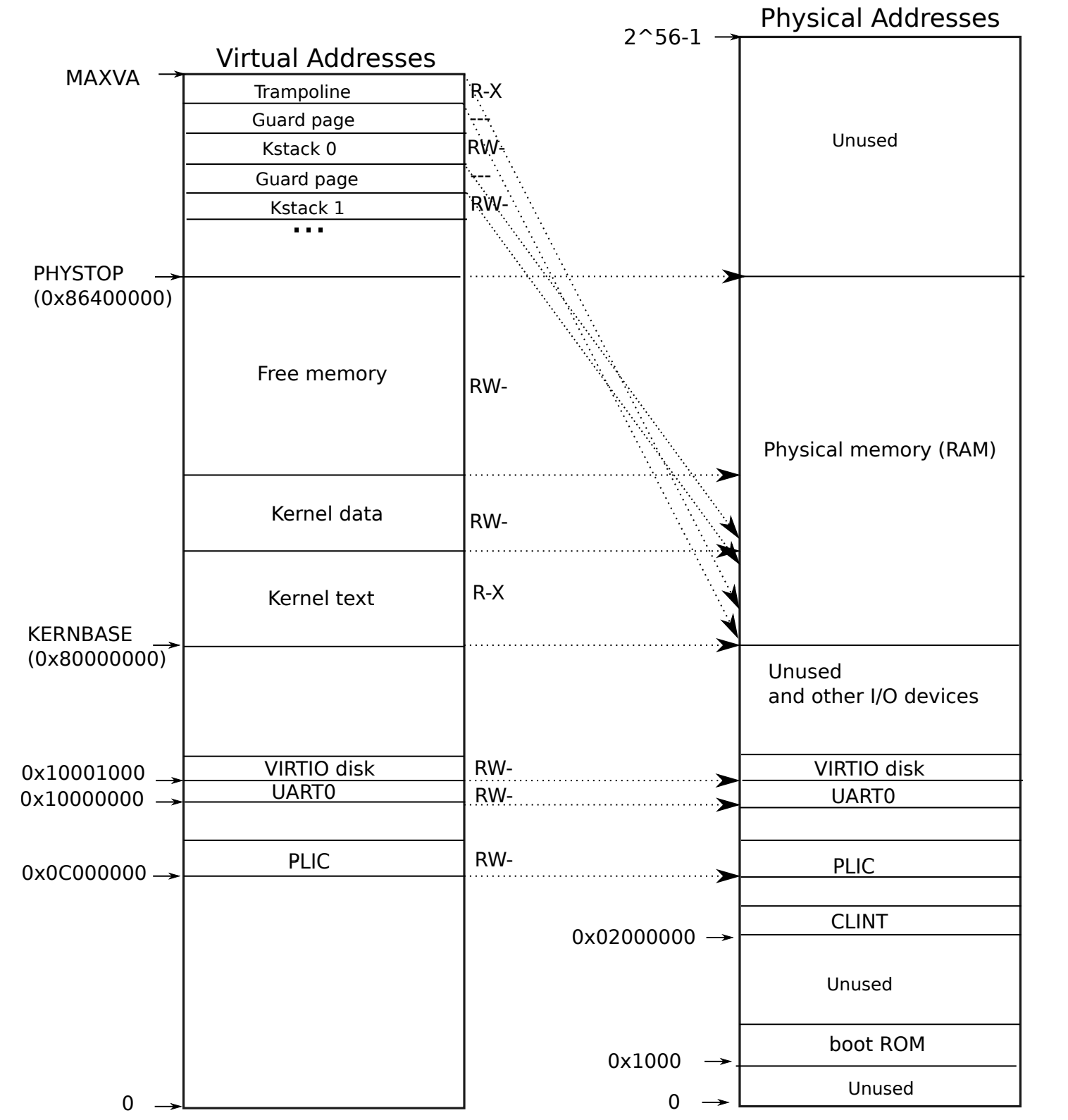
kernel 的内存布局
Trampoline ->0x3fffff000 - 0x40000000
Trapframe -> 0x3ffffe000 - 0x3fffff000
kernelstack for first process -> 0x3ffffd000 - 0x3ffffe000
Guard page -> 0x3ffffc000 - 0x3ffffd000
Kernelstack for second process ->0x3ffffb000 - 0x3ffffc000
Guard page -> 0x3ffffa000 - 0x3ffffb000
….
理解操作系统是怎么感知到空闲内存的, freerange函数,挂上一个free_mem链表, 想想可以有别的方法吗? 比如我想设置多种不同大小的pagesize, 比如 4KB/8KB/512KB/1MB/4MB/8MB/16MB等, 我该怎么写?
hints: multiple LinkedList理解trampoline 和kstack的本质是什么, 为什么映射的物理地址是这样子的 , trampoline和kstack的本质是什么?
hints: the content they savedXv6 是怎么引导到main函数执行的? 在lab2 syscall的时候,我们知道用户程序是通过elf.entry 来指定程序入口为main, 那xv6又是怎么做到的呢?
hints: start.c, entry.S? 为什么entry.S可以直接call start?如何读懂Makefile -> kernel.ld
如何看懂pgtable ,pgtable是va还是pa?
用户进程的kstack 是用来干嘛的?
Hints: 假设用户程序执行syscall 然后来了个clock interrupt 会发生什么事情?

LAB pgtable
print a page table (easy)
Define a function called
vmprint(). It should take apagetable_targument, and print that pagetable in the format described below. Insertif(p->pid==1) vmprint(p->pagetable)in exec.c just before thereturn argc, to print the first process’s page table. You receive full credit for this assignment if you pass thepte printouttest ofmake grade.
- 在kernel/vm.c 实现vmprint的逻辑 并在defs.h上进行声明, 这可以让其他文件使用vmprint函数
- 仔细学习freewalk函数
- 使用%p来打印64bits 的PTEs 还有对应的地址
A kernel page table per process (hard)
Your first job is to modify the kernel so that every process uses its own copy of the kernel page table when executing in the kernel. Modify
struct procto maintain a kernel page table for each process, and modify the scheduler to switch kernel page tables when switching processes. For this step, each per-process kernel page table should be identical to the existing global kernel page table. You pass this part of the lab ifusertestsruns correctly.
- 往struct proc 添加一个 kernel_pgtable 的指针
- 实现一个改良版的kvminit, 使得可以在allocproc的时候调用这个函数
- 确保用户进程的内核页表拥有对应 的kernel stack , 你需要修改procinit 并将对应逻辑放到allocproc这个函数里
- 修改scheduler函数, 使得satp寄存器指向用户进程的内核页表,当你调用w_satp()的时候, 不要忘记调用sfence_vma() ,scheduler应该使用内核页表,当没有用户进程在运行的时候
- 在freeproc中 释放用户进程的内核页表, 但是不要释放真正的内核页表
- 你可以在kernel.asm中 看到究竟是哪一行代码导致的page fault
这个kernel page per process 很多MIT本科生刷的时候都觉得很难的, 所以大家不要妄自菲薄, 最关键的问题在于你是否对xv6有了足够深刻的认识, 你才能很好的做完这个lab. 我来分析一下我是怎么实现这个lab的.
- 首先很直观的想法, 就是往用户页表里面copy 一份内核页表, 并添加对应 的mapping, 但其实你会发现这样做是不可行的, 因为如果其他用户进程修改了某些内核的数据,这会导致数据不一致的问题.
- 那么我们该怎么做呢? 思考一下xv6三级页表的结构,每一级页表都是存储对下一级页表的索引, 再仔细想想,我是不是只需要复制内核页表的一级页表就可以了, 于是我们可以kalloc 一个page, 并将一级页表的映射都给拷贝到这个page里面, 这样我们就可以根据这个一级页表去拿到内核的数据了. 听起来是不是很可行!
- 为什么要kstack 从procinit移出来呢?
Scause 对应的错误
| 异常编码 | 描述 |
|---|---|
| 0 | Instruction address misaligned |
| 1 | Instruction access fault |
| 2 | Illegal instruction |
| 3 | Breakpoint |
| 4 | Load address misaligned |
| 5 | Load access fault |
| 6 | Store/AMO address misaligned |
| 7 | Store/AMO access fault |
| 8 | Environment call from U-mode |
| 9 | Environment call from S-mode |
| 11 | Environment call from M-mode |
| 12 | Instruction page fault |
| 13 | Load page fault |
| 15 | Store/AMO page fault |
Simplify copyin/copyinstr (hard)
Replace the body of
copyininkernel/vm.cwith a call tocopyin_new(defined inkernel/vmcopyin.c); do the same forcopyinstrandcopyinstr_new. Add mappings for user addresses to each process’s kernel page table so thatcopyin_newandcopyinstr_newwork. You pass this assignment ifusertestsruns correctly and all themake gradetests pass.
- 让copyin函数调用copyin_new 函数, 使其正常运行之后,才继续写copyin_str
- 每次当内核需要改变用户页表的时候, 同时改变用户进程的kernel pgtable, 例如fork(),exec(), sbrk()
- 不要忘记initcode 进程的修改
- 思考在用户进程的kernel pgtable 的PTE权限是什么? (PTE_U 无法在kernel mode 中被访问)
- 不要让页表映射高于PLIC limit
- Copyin 函数究竟干了写什么东西
- 全部拷贝mappings, 为什么copyin_new 会work起来?
- 究竟什么是virtual memory? 如何理解virtual memory的机制? hints: PTE tag
Optional Challengge exercises
- 取消对用户页表 第一页的映射,当解引用一个null 指针的时候会生成一个page fault.
- 使用超级页表 来减少pagetable中PTE的数量
- 取消PLIC Limit的限制
感慨良多呀, 重刷 2020 lab pgtbl , 一个lab 就困了我3天, 最主要的问题就在于对页表的理解 还是太浅薄了 不够深刻, 所以还是写一篇博客来总结一下这几天关于页表的思考, 还是以QA的形式进行记录.
究竟什么是虚拟地址,什么是物理地址呢?
我们知道所谓的虚拟地址和物理地址都是针对于内存的概念, 所以下面会统称为虚拟内存和物理内存.我的理解是这样的
虚拟内存正如jyy所说的是给用户程序带上的VR眼镜, 构建出一个虚拟的世界让用户程序以为自己独占整个世界,但其实在背后是多个不同的用户程序和内核一起在共享整个内存. 而物理地址则是现实可索引的物理内存index, 在RISC-V中 只要MMU不工作的情况下, 你所接触到的地址都指的是物理地址, 比如xv6刚启动时, PC指向0x8000000 也就是entry.S的entry section, 然后开始执行section里面的指令, 这时候的地址就是物理地址. 直到执行kvminit函数 组装出一个三级页表的kernel_pagetable 并且kvminithart函数使得SATP寄存器指向kernel_pagetable之后,MMU才开始工作,从这一时刻开始 内核也带上VR眼镜, 他所面对的地址也需要经过MMU的翻译, 不过内核有自己摘下VR眼镜的权利(Turn off SATP register),但用户程序就只能永远带上VR眼镜了.在xv6中关于物理地址和虚拟地址的转换计算?
如果有仔细看过xv6的vmprint的结果的话, 我们会发现xv6的一级页表的512个pte里只有第0、2、255个pte是有值的, 其中pte为0 的物理地址指向二级页表对应的pte 也不是从0开始的, 只有4个pte 分别是16,96,97,128. 如下图所示

那这究竟是怎么回事呢? 这就需要说到从虚拟地址到物理地址转换的过程, 我们知道在内核中最低的物理地址就是CLINT 0x2000000,
并且xv6的内核页表是直接映射(也即虚拟地址和物理地址是一样的),那xv6的页表是怎么将虚拟地址0x2000000映射到CLINT的物理地址呢? 这需要对xv6的三级页表的建立过程有所了解, 其里面最核心的逻辑就是walk这个函数, 以上述的0x2000000为例, 我们来说一下三级页表的建立过程, 我们知道在内核看来一个虚拟地址是分成多个部分的, 如下图所示, EXT|L2|L1|L0|Offset, 当页表准备为虚拟地址0x2000000建立映射的时候, 他会将0x2000000 首先转化成一个64位的二进制, 由于xv6是Sv39 所以我们只需要关心后39bits就可以了, 至于前面的bits 在xv6里面都是0,是预留的扩展位. 总所周知一位十六进制数对应着4位二进制数, 那么我们的 0x2000000 就可以换算成 =
0010,0000,0000,0000,0000,0000,0000 一共28位二进制数, 也即虚拟地址的后28bits, 剩余39-28=11bits都是0, 假设我们按照下图的切割方法,将39bits 分成4团. 则得到L2 000,000,000 | L1 000,010,000 |L0 000,000,000 | offset 000,000,000,000 . 我们把二进制再转换成十进制(PTE是按十进制呈现的) 得到 L2= 0, L1 = 16, L0 = 0, offset = 0;
当xv6拿到L2,L1,L0之后,就可以建立对应的映射, L2= 0, xv6会查看kernel_pagetable[0]所对应的pte 是不是有效值(看PTE_V), 如果pte无效(没有被分配)的话, 则通过kalloc分配一个PGSIZE大小的内存作为一个二级页表(secondLevel pagetable), 并将这个二级页表的物理地址通过一定的权限设置(PTE flags设置)之后,存放在kernel_pagetable[0]处. L1=16,然后xv6会对刚刚分配的二级页表中查这个secondLevel pagetable[16]所存放的pte是否是个有效值, 由于刚分配这个二级页表,所以这个PTE肯定也是无效值, 因此 这个时候也会通过kalloc 分配一个PGSIZE大小的内存作为一个三级页表(thirdLevel pagetable),并将这个三级页表的物理地址经过一定运算之后放回到 secondLevel pagetable[16]. 这时候来到了三级页表 L0=0, xv6会查看thirdLevel pagtable[0] 是否是个有效值, 众所周知刚分配个肯定都是无效值. 因此 xv6会通过kalloc 分配一个PGSIZE大小的内存作为真正存放数据的地方, 然后把这个地方的物理地址经过一定运算之后放回到 thirdLevel pagetable[0] , 至此 thirdLevel pagetable[0] 就存放着CLINT的物理地址. 我们也就结束了将虚拟地址0x2000000 映射到物理地址0x2000000的过程, (其他物理也是同理) 我们通过三级页表可以将一个虚拟地址翻译成物理地址了.
现在我们就能知道为什么vmprint打印的值为什么这么奇怪了. 那我们知道PLIC的虚拟地址是0xc000000, 对应的28bits 为1100,0000,0000,0000,0000,0000,0000 填充0到39bits 得到 L2=0, L1=96,L0=0,offset=0. 也即一级页表第0项,二级页表第96项,三级页表第0项. 那我们看看内核基址 0x80,000,000 会映射在哪? 我们知道内核基地是8位十六进制也就是32bits, 再把前7bits填充0,得到一个39bits团,得到L2=000,000,010 L1=000,000,000 L0=000,000,000 offset=000,000,000,000. (L2=2,L1=0,L0=0) 这也解释了为什么vmprint的 kernel_table[2]指向的二级页表连续存放了这么多有效的pte. 如果你看这些二级页表指向的三级页表,你会发现这些三级页表也都是满的.
- 为什么页表带来了这么高的复杂度, 并且要连续3次访问内存才能拿到一个物理地址,我们还需要虚拟内存呢?
这是一个好问题, 一个技术的出现肯定是为了解决一些已知问题. 在我看来虚拟内存主要解决了以下几个问题
- 内存不足:在使用虚拟内存之前,操作系统需要将所有进程所需的物理内存完全映射到它们的虚拟地址空间中。这样往往会导致内存不足的问题,因为进程的内存需求可能会随着时间变化而变化。虚拟内存可以将进程的虚拟地址空间映射到物理内存上,并且只有当进程需要访问某个页面时才将其加载到物理内存中(Lazy Load)。这样可以极大地节省物理内存的使用,从而避免了内存不足的问题。(参考8GB的运行内存,却可以玩16GB的绝地求生游戏)
- 大内存需求:某些应用程序需要处理非常大的数据集,超出了实际可用的物理内存大小。虚拟内存技术可以将磁盘上的数据交换到物理内存中,从而允许应用程序使用比实际物理内存更大的内存。(参考Linux的swap分区)
- 内存保护:虚拟内存技术可以对进程使用的内存进行抽象和保护,防止不同进程之间发生内存冲突或篡改,提高了系统的安全性和稳定性.
- 进程隔离:每个进程都有自己的虚拟地址空间,使得多个进程之间相互隔离,从而提高了系统的稳定性和安全性,并且便于进行优化和调度。
- 灵活性和扩展性:虚拟内存使得操作系统和应用程序的设计更加灵活和可扩展。由于虚拟内存可以为每个进程提供一个独立的地址空间,因此可以更容易地进行进程切换、共享内存等操作。同时,也使得应用程序可以更好地适应不同的硬件环境和内存大小。
虚拟内存不仅解决了这些问题, 而且还带来了很多的好处
内存共享:多个进程可以共享同一块物理内存(只要建立一样的映射就可以了,参考kernel pagetable per process),从而实现资源共享,提高系统效率
统一内存抽象:虚拟内存使得操作系统可以将物理内存和二级存储器(如磁盘)和一些硬件设备 统一抽象为一组逻辑地址,简化了系统的管理和维护,降低了应用层程序员的心智负担、
内存保护:虚拟内存可以将一部分内存区域设置为只读或者不可执行(设置PTE flag),保护系统和应用程序的稳定性和安全性
减少内存碎片:在使用虚拟内存的情况下,操作系统可以将物理内存划分为许多大小相等的页面。当一个进程申请内存时,操作系统会分配一定数量的页面来满足该进程的需求,并将这些页面映射到该进程的虚拟地址空间中。当进程不再需要这些页面时,操作系统则会回收它们。 但是这也会带来IO放大, 比如我只想申请一个8Bytes大小的内存, 我们却需要向操作系统申请一个4KB的内存, 虽然libc 帮我们做了一些工作 减缓了这种现象
机制简化:虚拟内存把内存管理从应用层转移到内核层,使得应用程序无需关心物理内存的具体情况,减少了编程复杂度